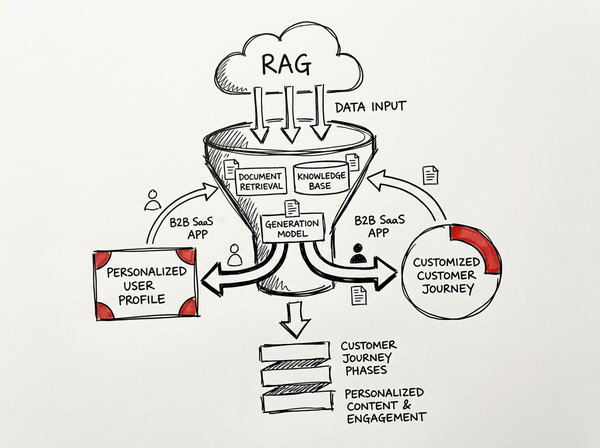
The lightweight token-saving approach demonstrated by Zoe relies on strict context compression, structured outputs, and the elimination of conversational filler from LLM prompts.
Porting this extreme token efficiency to a scalable orchestration system like CrewAI transforms expensive, bloated multi-agent loops into highly profitable, production-ready workflows. By systematically